Following the lead of The Matilda Project The Alibi Library has decided to produce a short series highlighting the work of some of the best fictional libraries:
Imagine a library…

a universe of books http://www.nysun.com
Imagine a library whose proportions are so intangible to the likes of ordinary mortals like you and me that they have become a mathematical enigma. Here are some values just to begin with:
- The average large library on Earth at the present time typically contains only several million volumes, i.e. on the order of about
 books.
books. - The world’s largest library, the Library of Congress, has
 books.
books. - The Library of Babel contains at least
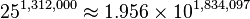 books.[2]
books.[2]
A mathematician´s dream come true and a librarian´s nightmare. Just imagine that the books could be arranged in  ways.[3][4]
ways.[3][4]
“The Library of Babel” (La biblioteca de Babel) is a story by author and librarian Jorge Luis Borges (1899–1986), conceiving of a universe in the form of a vast library containing all possible 410-page books of a certain format.
The story was originally published in Borges’s 1941 collection of stories El Jardín de senderos que se bifurcan (The Garden of Forking Paths).

borgesdesmazieres
The Library
consists of an enormous expanse of interlocking hexagonal rooms, each of which contains four walls of bookshelves and the bare necessities for human survival. The order and content of the books is random and apparently completely meaningless.
The universe (which others call the Library) is composed of an indefinite and perhaps infinite number of hexagonal galleries, with vast air shafts between, surrounded by very low railings. From any of the hexagons one can see, interminably, the upper and lower floors. The distribution of the galleries is invariable. Twenty shelves, five long shelves per side, cover all the sides except two; their height, which is the distance from floor to ceiling, scarcely exceeds that of a normal bookcase. One of the free sides leads to a narrow hallway which opens onto another gallery, identical to the first and to all the rest. To the left and right of the hallway there are two very small closets. In the first, one may sleep standing up; in the other, satisfy one’s fecal necessities. Also through here passes a spiral stairway, which sinks abysmally and soars upwards to remote distances. In the hallway there is a mirror which faithfully duplicates all appearances. Men usually infer from this mirror that the Library is not infinite (if it were, why this illusory duplication?); I prefer to dream that its polished surfaces represent and promise the infinite … Light is provided by some spherical fruit which bear the name of lamps. There are two, transversally placed, in each hexagon. The light they emit is insufficient, incessant.

The Books
The books contain every possible ordering of just a few basic characters (23 letters, spaces and punctuation marks) and are exactly 410 pages long.
There are five shelves for each of the hexagon’s walls; each shelf contains thirty-five books of uniform format; each book is of four hundred and ten pages; each page, of forty lines, each line, of some eighty letters which are black in color. There are also letters on the spine of each book; these letters do not indicate or prefigure what the pages will say. I know that this incoherence at one time seemed mysterious. Before summarizing the solution (whose discovery, in spite of its tragic projections, is perhaps the capital fact in history) I wish to recall a few axioms.
Though the majority of the books in this universe are pure gibberish, the library also must contain, somewhere, every coherent book ever written, or that might ever be written, including predictions of the future, biographies of any person, and translations of every book in all languages, and indeed, every possible permutation or slightly erroneous version of every one of those books.
for every sensible line of straightforward statement, there are leagues of senseless cacophonies, verbal jumbles and incoherences
For example for every authentic book there will be:
- Variants with one misprint:
 = 31,488,000
= 31,488,000 - Variants with exactly two misprints:
 = 495,746,694,144,000
= 495,746,694,144,000 - Variants with exactly three misprints:
 = 5,203,349,369,788,317,696,000
= 5,203,349,369,788,317,696,000 - Variants with exactly four misprints:
 = 40,960,672,578,684,980,713,193,472,000
= 40,960,672,578,684,980,713,193,472,000
Just one “authentic” volume, together with all those variants containing only a handful of misprints, would occupy so much space that they would fill the known universe.

stewart_borges2 http://www.mhpbooks.com
The Librarians
The glut of information leaves the librarians, chief librarians, genius librarians etc in a state of suicidal despair. This leads some librarians to have superstitions and cult-like behaviour, such as the “Purifiers”, who arbitrarily destroy books they deem nonsense as they scour through the library seeking the “Crimson Hexagon” and its illustrated, magical books. Another is the belief that since all books exist in the library, somewhere one of the books must be a perfect index of the library’s contents; some even believe that a messianic figure known as the “Man of the Book” has read it, and they travel through the library seeking him.
pilgrims disputed in the narrow corridors, proferred dark curses, strangled each other on the divine stairways, flung the deceptive books into the air shafts, met their death cast down in a similar fashion by the inhabitants of remote regions. Others went mad …
There are also inquisitors, official searchers, who
always arrive extremely tired from their journeys; …speak of a broken stairway which almost killed them; they talk with the librarian of galleries and stairs; sometimes they pick up the nearest volume and leaf through it, looking for infamous words. Obviously, no one expects to discover anything.

searching the library of babel therumpus.net
The Clients
are called travellers. The narrator who is himself a traveller tells us:
Like all men of the Library, I have traveled in my youth; I have wandered in search of a book, perhaps the catalogue of catalogues; now that my eyes can hardly decipher what I write, I am preparing to die just a few leagues from the hexagon in which I was born.

arcimboldo_librarian_stokholm
More information about the library can be found at the following links:
Digital Access to the Books of the Library
Wikipedia:

Good day! I just want to give an enormous thumbs up for the
good information you’ve got here on this post.
I shall be coming back to your weblog for extra soon.